Was ist ein Index?
Als „Index“ wird allgemein ein geordnetes Verzeichnis, auch Register, in einem Nachschlagewerk (bspw. Lexikon, Telefonbücher, etc..) bezeichnet. Der sogenannte „Google Index“ ist die Gesamtheit aller von Google erkannten, d.h. gecrawlten, und gespeicherten (=indexierten), Webseiten. Die SERPs sind ausschließlich mit Seiten aus dem Index gefüllt – eine Seite die nicht im Index ist, wird auch nicht in den SERPs stehen.
Der Google Index ist nicht, wie in einem Lexikon, statisch, sondern höchst dynamisch. Neue Webseiten kommen hinzu, manche werden entfernt. Durch Crawler, die von Link zu Link springen, werden neue Seite erfasst. Verstößt eine Webseite massiv gegen die Google Richtlinien, wird eine Webseite aus dem Index, und damit aus den SERPs, entfernt.
Zusätzlich ist der Google Index komplex gegliedert. Das bedeutet, er ist nicht nur alphabetisch aufgebaut, sondern es werden verschiedene Rankingkriterien über den Index gelegt, um für eine Suchanfrage ein bestimmtes Set an Webseiten in einer bestimmten Reihenfolge auszuliefern. Dies passiert ebenfalls dynamisch, da sich Webseiten und die Rankingkriterien beständig ändern. Wie dies genau funktioniert, ist Betriebsgeheimnis Googles.
Dies gilt analog für alle anderen Suchmaschinen. Oftmals wird im Netz der Ausdruck „indiziert“ für „indexiert“ verwendet, was aber falsch ist.

Wie Google den Index füllt
Google reichert seinen Index mit Hilfe von Crawlern (auch Bots genannt), an. Ein Crawler springt von einem Link zu einem anderen und trifft in der Folge auf miteinander verlinkte Webseiten. Jede neue Webseite wird gecrawlt, d.h., der Quellcode wird ausgelesen und an den Index gesendet. Dort wird die Seite nach verschiedensten Rankingfaktoren und anderen Regeln einsortiert. Wer seine Webseite auf diese Weise indexieren lassen will, muss also dafür sorgen dass sie von einer anderen Webseite einen Link bekommt. Dann muss ein Crawler auf der fremden Webseite vorbeischauen und den Link zu unserer Seite entdecken. Diese Möglichkeit der Indexierung ist recht langwierig und unsicher.
Eine Webseite indexieren lassen
Um aktiv seine Seite indexieren zu lassen, kann man seine Webseite direkt an Google „schicken“. Dafür gibt es drei Möglichkeiten:
a) Unter http://www.google.de/addurl/ kann man einen Antrag auf Indexierung für eine Webseite stellen. Eine erfolgreiche Übermittlung der Daten ist aber keine Garantie auf eine Aufnahme. Zudem muss man ein Google Konto besitzen, um auf diesen Dienst zugreifen zu können. Wenn man schon ein Google Konto hat, ist es sinnvoller eine andere Möglichkeit zu nutzen:
b) In den Webmaster Tools (auch „Search Console“ genannt), kann man eine Sitemap direkt an Google schicken.
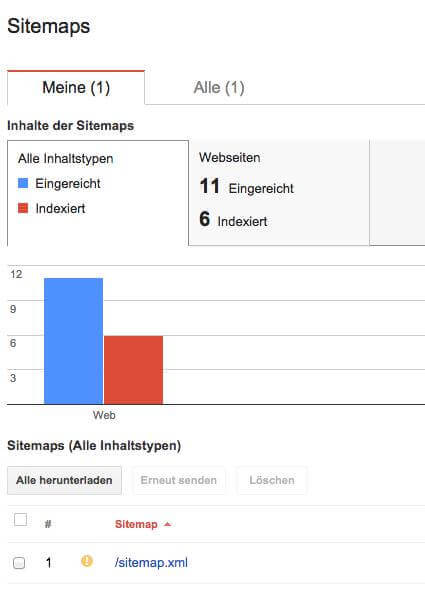
Eine Sitemap kann man sich recht unkompliziert im .xml Format erstellen lassen, im Netz gibt es viele, kostenlose Dienste dazu. Diese .xml Datei fügt man in den Webmaster Tools unter „Sitemaps“ hinzu:

Nach einiger Zeit, in der Regel in den nächsten 24 Stunden, wird Google die in der Sitemap angegeben URLs crawlen. Den Fortschritt der Indexierung kann man in den Webmaster Tools unter „Sitemaps“ verfolgen:
c) Will man eine einzelne Seite indexieren lassen, bspw., weil sie nach der Erstellung der Sitemap hinzugekommen ist, hat man in den Webmaster Tools unter „Crawling“ → „Abruf wie durch Google“, die Möglichkeit eine einzelne URL an den Index zu senden.
Eigentlich ist diese Option dazu da, um zu überprüfen ob der Crawler alle Ressourcen auf einer Seite sehen und verstehen kann (JavaScript, etc.). Nachdem man aber die URL abgeschickt hat, bietet Google die Möglichkeit an, die URL „an den Index“ zu senden.

Damit wird aber nur die eine URL und eventuell auf dieser URL verlinkte Seiten der Domain an den Index gesendet. Jedes Konto hat eine monatliches Kontingent von 10 URLs die an den Index gesendet werden können.
Eine Indexierung verhindern
Es kann mehrere Gründe geben, wieso ein Webmaster verhindern will, dass seine Seite in den SERPs auftaucht und damit im Google Index vorhanden ist.
– Die Seite ist noch nicht fertig oder befindet sich im Relaunch und soll bis zur Fertigstellung nicht gefunden werden.
– Es gibt urheber- oder datenschutzrechtliche Gründe die Seite nicht öffentlich verfügbar zu machen.
– Manchmal möchte ein Webmaster einzelne Unterseiten nicht öffentlich machen, bspw. Admin-Zugänge oder minderwertige Seiten.
– Die Webseite ist nur für den privaten Gebrauch bestimmt.
Es gibt mehrere Möglichkeiten eine Indexierung zu verhindern
a) Meta-Tag „noindex“
Mit dem Meta-Tag „noindex“ gibt man dem Crawler die Anweisung, die Seite nicht zu indexieren:
<meta name=”robots” content=”noindex”/>
Auch wenn sich die meisten Suchmaschinen-Crawler daran halten, ist der noindex-Tag nur eine Anweisung.
b) Crawler mit der robots.txt aussperren
In der robots.txt fügt man folgenden Code ein, um alle Seiten einer Domain für alle Zugriffe zu sperren:
User-agent: *
Disallow: /
Will man nur einzelne Unterordner ausschließen, sieht das Ganze so aus:
User-agent: *
Disallow: /unterordner1
Disallow: /unterordner2/unterordner/
c) Crawler per .htaccess ausschließen
Mit der .htaccess kann man ein Passwortschutz für die gesamte Webseite oder einzelne Bereiche der Seite festlegen. Diese Option wird auch von Google empfohlen: URLs durch passwortgeschützte Serververzeichnisse blockieren (https://support.google.com/webmasters/answer/93708?hl=de)
Eine detaillierte Anleitung findet man u.a. hier: http://www.grammiweb.de/anleitungen/ka_htaccess.shtml
Aus dem Index fliegen – und wieder reinkommen
Unfreiwillig aus dem Index fliegen ist sehr ärgerlich. Um wirklich de-indexiert zu werden, muss man sich aber schon einiges zu Schulden kommen lassen – etwa massives, auf breiter Basis angelegtes, Spam–Linkbuilding, oder groß angelegtes Cloaking. Aber auch negatives SEO, also wenn Konkurrenten oder Hacker SEO-Technisch gegen die eigene Seite Vorgehen, kann ein Grund sein aus dem Index zu fliegen.
– Als erstes richtet man einen Wiederaufnahmeantrag (Reinclusion Request oder auch Reconsideration Request) an Google.
– Wenn man selber Mist gebaut hat, muss man nachweisen dass man es wieder gut gemacht hat.
– Wenn man Opfer eines Angriffes wurde, sollte man auch das nachweisen können.
In den Webmaster Tools stellt man nun einen „Antrag auf erneute Überprüfung“ der in der Nachricht zur Abstrafung zu finden ist.
Nun kann es etwas dauern, erfahrungsgemäß zwischen 2 und 12 Wochen, bis die Seite wieder im Index ist.
Siehe auch: Unsere Ratgeberartikel zum Thema