Was ist ein Canonical Tag?
Der Canonical Tag wird eingesetzt, um Webseiten mit doppeltem Inhalt (Duplicate Content) richtig auszuzeichnen. Dieser wird, sobald er von Google erkannt wird, abgestraft. Das heißt, die Seite mit dem sich wiederholenden Inhalt rankt schlechter in den Suchergebnissen. Im Headerbereich des Quelltextes wird er innerhalb eines Link-Elements mit dem Attribut rel=“canonical“ gekennzeichnet. So verlinkt man von einer oder mehreren Kopien einer Website auf das Original. Diese Ursprungsseite wird auch als die „kanonische“ Seite bezeichnet.
Scannt ein Crawler eine Webseite und findet darauf einen Canonical Tag, erkennt der Bot dass die verlinkte Seite das „eigentliche“ Original ist, die „kopierten“ Webseiten also im Hinblick auf Duplicate Content ignoriert werden können. Außerdem werden durch die Suchmaschine wie bspw. Google Eigenschaften wie etwa PageRank auf das Original übertragen. Somit ist der Canoncial Tag ein wichtiges Werkzeug für die OnPage Optimierung und zur Vermeidung von Fehlern in der Bewertung von Inhalten. [1]
Wann wird der Canonical Tag eingesetzt?
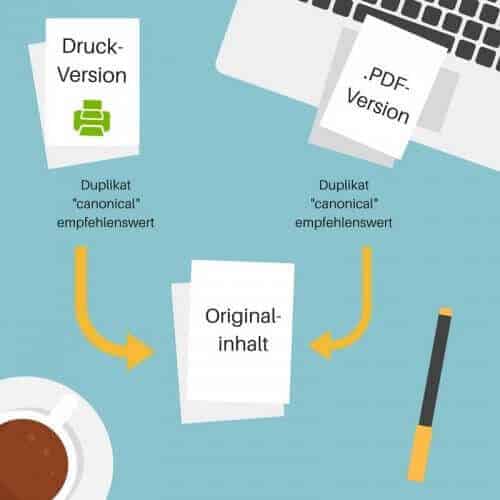
Online-Shops, deren Produkte einmal nach Farbe und einmal nach Preis sortiert werden können, bekommen dadurch recht viel Duplicate Content. Auch Blogs, die ein und denselben Inhalt öfter anzeigen wollen, bspw. wenn ein Artikel über Schokoladendesserts unter der Kategorie „Desserts“ und „Schokolade“ auftauchen soll, haben Duplicate Content. Das ist deshalb problematisch, weil bei fehlender Auszeichnung durch einen Canonical Tag auf diese Weise die Indizierung der Inhalte willkürlich erfolgt beziehungsweise der Inhalt eine Abwertung erhalten kann. Weiterhin kann ein Canonical Tag eingesetzt werden, wenn der Inhalt einer Seite unter einer weiteren URL zum Beispiel als Druckversion oder PDF angeboten wird, wie dies häufig bei Pressemitteilungen der Fall ist.
Zudem ist für sogenannten „technischen Duplicate Content“, also wenn die Seite mit und ohne www oder https erreichbar ist, ein Canonical Tag hilfreich. Dies trifft im Besonderen für Standard-URLs wie zum Beispiel „index.html“ und „home.html“ zu, welche auf den gleichen Inhalt verweisen.
Auch beim Anlegen eigenständiger mobiler Webseiten (zum Beispiel: m.Beispielseite.de) mit eigener URL empfiehlt sich die Verwendung von Canonical Tags, so dass der Vorteil der mobilen Optimierung nicht zum Nachteil wird.
Mittels Canonical Tag gibt man ein eindeutiges Zeichen an die Crawler der Suchmaschinen, welcher Inhalt als der relevantere zu bewerten ist und vermeidet Fehler beim Bewerten der Seite durch die Algorithmen. [2]
Wie wird der Canoncial Tag eingesetzt?
Für den Einsatz von Canonical Tags gibt es zwei Möglichkeiten:
Zum einen nutzt man den Quellcode der Inhaltsseite, welche die Kopie einer Seite darstellt (bspw.: „www.beispiel.de/kopie-der-original-url“) und fügt hier im HEAD-Bereich oder im HTTP-Header folgenden Code ein:
<link rel=”canonical” href=”http://www.beispiel.de/original-url”/>
Es kann je URL nur ein Canonical ausgelesen werden. Sollten sich im Quelltext mehrere Canonical Tags finden, werden diese von den Suchmaschinen ignoriert und die Seite wird dennoch indiziert.
Wichtig hierbei ist, dass man darauf achtet das innerhalb dieses Quellcodes keine Meta-Tags wie „nofollow“, „disallow“ oder „noindex“ vergeben worden sind, da diese sich in Ihrer Funktionalität mit dem Canonical Tag behindern können. Es ist darauf zu achten, welche der URLs mit dem Canonical Tag ausgezeichnet werden, da diese von Suchmaschinen wie z.Bsp. Google nicht gelistet werden.
Die zweite Variante ist das Übergeben der Canonical-Eigenschaft über den Server. Wird zum Beispiel in einem Online-Shop eine Einkaufskorb-Seite generiert, sendet der Server die Information mit, dass diese ein „Canonical Tag“ für die Ursprungsseite erhält. So kann vermieden werden, dass automatisch generierte Seiten Duplicated Content erschaffen.
Dies ist auch dann sinnvoll, wenn die Besucher der Website Inhalte per IDs filtern können. Etwa in Onlineshops sich nur „grüne“ Artikel anschauen. Auf der durch das System erschaffenen Seite wären die Inhalte gleich der Ursprungsseite – obwohl diese auf einer neuen URL angezeigt werden. Auch in diesem Fall empfiehlt sich die Übergabe der Canonical-Eigenschaft innerhalb des Link-Attributes für die Originalseite innerhalb des Quelltextes. [3]
Was ist beim Einsatz des Canonical Tags zu beachten?
- Bevor der Canonical-Tag verwendet wird, unbedingt prüfen, ob wirklich Duplicate Content vorliegt.
Die Inhalte der Seiten sollten tatsächlich identisch oder in großen Teilen gleich sein.
Es gibt verschiedene Duplicate-Content-Checker als online-Tool die dies übernehmen.
Wenn zum Beispiel Artikel in einem Blog in mehreren Sprachen vorliegen, wird dies durch die Suchmaschinen nicht als gleicher Inhalt bewertet, auch wenn die gemachte Aussage im Text übereinstimmt.
Video-Erklärung von Matt Cutts / Google
- Die durch den Canonical-Tag ausgezeichnete URL muss erreichbar sein und darf nicht auf eine 404-Seite verweisen. Das passiert beispielsweise wenn ein „www.“ vergessen wird oder die angesteuerte Website eine geänderte url aufweist.
- Die URL muss die exakte Bezeichnung haben; auch ein zusätzlicher oder fehlender Slash (Schrägstrich) oder „/index.php“ am Ende kann einen falschen Canonical-Tag verursachen.
- Es darf immer nur ein Canonical Tag pro Webseite verwendet werden, andernfalls ignorieren Suchmaschinen wie Google diese Auszeichnung.
- Es sollten immer absolute URLs (mit http://) verlinkt werden. Der Canonical Tag akzeptiert auch relative URLs (beispiel.de/artikel), allerdings wird die verlinkte Seite dann mit verlinkt.
- Die verlinkte Seite sowie die URL mit Canonical Tag darf kein „noindex“, „nofollow“ oder „disallow“ Meta-Tag aufweisen.
- Seiten mit einem Canonical-Link werden nicht für die Suchergebnisse berücksichtigt – mit Ausnahme der Seiten, die mit einem Canonical-Link auf sich selbst verweisen, um möglichen URL-Generierungen über Session-IDs vorzubeugen.
- Bei paginierte Seiten, die mit rel=“next“ bzw. rel=“prev“ ausgezeichnet sind, ist der Einsatz von Canonical Tags nicht sinnvoll (da an dieser Stelle kein eigentlicher Duplicate Content vorhanden ist). [3]