
Google Fonts & Co.: Webseiten auf das ungefragte Laden von externen Ressourcen überprüfen
Viele Website-Betreiber*innen nutzen auf ihren Websites Ressourcen, die nicht von der eigenen Domain abgerufen, sondern dynamisch von anderen Quellen eingebunden werden. Dazu zählen beispielsweise JavaScript-Code-Snippets zur Aussteuerung von Tracking Tools wie Google Analytics oder das Facebook Pixel, Widgets zum Einbinden von Kartendiensten wie Google Maps, oder Social-Media-Inhalte wie YouTube-Videos, Twitter-Nachrichten & Co.
Auch Schriftarten wie Google Fonts werden oft direkt vom Google-Server geladen, was erst kürzlich zu einer Abmahnwelle führte. Auch wenn diese Massenschreiben in ihrer Form zweifelhaft waren, brachten sie das wichtige aber dennoch häufig wenig beachtete Thema auf die Tagesordnung: Externe (also von Quellen außerhalb der eigenen Website-Domain eingebundene) Ressourcen sollten nie ohne Zustimmung der Website-Besucher*innen geladen werden, da durch den Zugriff auf die ursprünglichen Quellen dieser Inhalte bereits ein Datenaustausch (z. B. der IP-Adresse, die oft als personenbezogenes Datum definiert wird) mit einem Fremd-Server stattfindet.
Wie können externe Ressourcen in Websites eingebunden sein?
Es gibt verschiedene Möglichkeiten, wie Ressourcen von externen Quellen in Websites eingebunden werden können. Einige davon sind zum Beispiel:
Website Ressoucen per iframe einbinden
Über das <iframe>-Tag können Bereiche innerhalb von Webseiten definiert werden, in denen Inhalte von externen Websites dargestellt werden. Diese Inhalte werden direkt von der externen Quelle geladen. Ein Beispiel dafür ist die Einbettung von YouTube-Videos:
<iframe width="560" height="315" src="https://www.youtube.com/embed/kiit_VnU4c0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
Beim Laden der iframe-Inhalte findet ein Datenaustausch mit der im src-Attribut angegebenen Domain statt, im Beispiel also mit youtube.com.
Hinweis: YouTube bietet beim Einbetten von Videos via iframe die Möglichkeit zur Aktivierung eines „Erweiterten Datenschutzmodus“ an. Dieser ersetzt die Domain youtube.com im src-Attribut durch youtube-nocookie.com.
<iframe width="560" height="315" src="https://www.youtube-nocookie.com/embed/kiit_VnU4c0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
Laut YouTube werden dadurch keine Nutzerinformationen gespeichert, „es sei denn, sie sehen sich das Video an“. Aus Datenschutzperspektive wird aber dennoch ungefragt auf die externe Domain zugegriffen und damit mindestens die IP-Adressen der Website-Besucher*innen an YouTube übermittelt.
Externe Ressourcen per JavaScript-Code-Snippet einbinden
Das <script>-Tag ermöglicht es, JavaScript-Code in der Website auszuspielen. Dieser Code kann entweder direkt innerhalb der <script>-Tags hinterlegt werden oder es wird per src-Attribut auf ein separates Dokument verwiesen, in dem der JavaScript-Code hinterlegt ist. Dieses Dokument kann entweder innerhalb der Website-Domain liegen oder auch von externen Domains geladen werden. Letzteres ist häufig bei Tracking Tools wie Google Analytics oder dem Facebook Pixel der Fall:
<script async src="https://www.googletagmanager.com/gtag/js?id=G-XXXXXXXXXX"></script> <script> window.dataLayer = window.dataLayer || []; function gtag(){dataLayer.push(arguments);} gtag('js', new Date()); gtag('config', 'G-XXXXXXXXXX'); </script>
Im Beispiel ist das JavaScript-Code-Snippet für das Tracking in einen Google Analytics 4 Datenstream abgebildet. Der für das Tracking nötige JavaScript-Code wird von der Domain googletagmanager.com geladen.
Hinweis: Wird das Google Analytics Tracking über den Google Tag Manager realisiert, dann muss statt des Google Analytics Code Snippets der JavaScript-Code für den genutzten Google Tag Manager Container in der Website eingebunden werden. In dem Fall ist kein src-Attribut im öffnenden <script>-Tag eingefügt, sondern die Quelle für den von extern zu ladenden JavaScript-Code wird innerhalb des Code-Abschnitts zwischen den <script>-Tags hinterlegt. Dasselbe Prinzip findet sich bei anderen Tracking Tools, wie beispielsweise den Tracking-Pixeln für Facebook und TikTok.
<script>(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({'gtm.start':
new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0],
j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src=
'https://www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f);
})(window,document,'script','dataLayer','GTM-XXXXXXX');</script>
Auch wenn in dem Google Tag Manager Container keinerlei Tracking Tags konfiguriert sind, stellt bereits das Laden der JavaScript-Datei von googletagmanager.com einen Datenaustausch mit einem Google-Server dar und sollte damit niemals ohne Zustimmung durch die Website-Besucher*innen erfolgen.
Per Verweis auf eine externe Ressource
Mit dem <link>-Tag können im HTML-Quellcode Beziehungen zwischen der aktuellen Seite und externen Ressourcen spezifiziert werden. Damit werden üblicherweise CSS-Stylesheets zur Definition des Website-Layouts sowie Favicons und Icons zur Darstellung auf Home Screens von Mobilgeräten verlinkt. Aber auch Schriftarten wie Google Fonts können darüber referenziert werden:
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Open+Sans:wght@300&display=swap" rel="stylesheet">
Über das href-Attribut wird die Quelle der referenzierten Ressource angegeben. Im gezeigten Beispiel wird die Schriftart Open Sans Light 300 dynamisch von der Domain fonts.googleapis.com geladen, was einen Datenaustausch mit einem Google-Server darstellt und damit – wenn die Schriftarten wie hier über die fonts.googleapis.com-Domain und nicht lokal über die eigene Website-Domain eingebunden sind – zustimmungspflichtig ist.
Per direkter Einbindung einzelner Seitenelemente
Über das zuvor vorgestellte <iframe>-Tag können ganze Abschnitte von Fremd-Websites innerhalb der eigenen Website dargestellt werden. Es jedoch auch möglich, über das src-Attribut einzelne HTML-Elemente wie zum Beispiel Bilder direkt von anderen Domains zu laden:
<img src="https://www.seo-kueche.de/wp-content/themes/seo-kueche/_/img/logo.svg" alt="SEO-Küche" width="141" height="90" style="width: auto; height: auto">
Im gezeigten Beispiel wird das Bild direkt von der eigenen Website-Domain seo-kueche.de geladen. Die Quelle ist über das src-Attribut definiert.
Manche Websites legen solche Elemente ggf. nicht innerhalb der eigenen Website-Domain ab, sondern nutzen dafür so genannte Content Delivery Networks (CDN). Das sind geografisch verteilte Verbünde von hochperformanten Servern, die dafür sorgen, dass die geladenen Inhalte möglichst schnell den Website-Besucher*innen ausgespielt werden. Die Quelle dieser Inhalte ist dann nicht die eigene Website-Domain, sondern die Domain des CDN.
<img src="https://seo-kueche.beispiel-cdn.com/logo.svg" alt="SEO-Küche" width="141" height="90" style="width: auto; height: auto">
Das src-Attribut verweist in unserem Beispiel nun nicht mehr auf die eigene Website-Domain, sondern auf die Domain des Content Delivery Networks. Damit findet hier auch ein Datenaustausch mit einem Server außerhalb der eigenen Website-Domain statt, welcher aus Datenschutzperspektive in der Regel zustimmungspflichtig sein sollte.
Wie kann ich überprüfen, ob auf meiner Website externe Ressourcen ohne Zustimmung geladen werden?
Für einzelne Unterseiten über die Browser Entwickler-Tools
Die beim Aufruf einzelner Seiten einer Website geladenen Ressourcen lassen sich direkt im Browser überprüfen. In Google Chrome geht dies in den Chrome Entwickler-Tools unter Google Chrome > Anzeigen > Entwickler > Entwicklertools. In Firefox stehen diese unter Firefox > Extras > Browser-Werkzeuge > Web Developer Tools zur Verfügung.
Wir löschen alle Cookies der Website-Domain (am besten über das Schloss-Symbol neben der URL > Cookies > entfernen), rufen die eben erwähnten Entwickler-Tools auf und öffnen dort den Tab „Network“. Nun laden wir die zu überprüfende Seite der Website. Wir gelten jetzt als Erstbesucher und uns sollte ein eventuell implementiertes Cookie-Consent-Banner angezeigt werden. Externe Dienste und Ressourcen dürfen zu dem Zeitpunkt üblicherweise noch nicht geladen werden.
In den Entwickler-Tools werden im Tab „Network“ in der Spalte „Domain“ alle Domains aufgelistet, von denen Ressourcen während dieses Erst-Ladevorgangs abgerufen werden. Sollte die Spalte „Domain“ standardmäßig nicht angezeigt werden, so kann man sie mit Rechtsklick auf einen anderen Spaltenkopf in die Darstellung einfügen. Zur besseren Übersicht sollten die Einträge dieser Spalte zudem mit Klick auf den Spaltenkopf auf- oder absteigend alphabetisch sortiert werden.
Da wir noch keine Zustimmung für die Nutzung von externen Diensten gegeben haben, sollten hier nur die folgenden Einträge angezeigt werden:
- die Domain der zu überprüfenden Website
- die Domain des genutzten Cookie-Consent-Banners
- Einträge mit kryptischen Zeichenfolgen
- leere Einträge
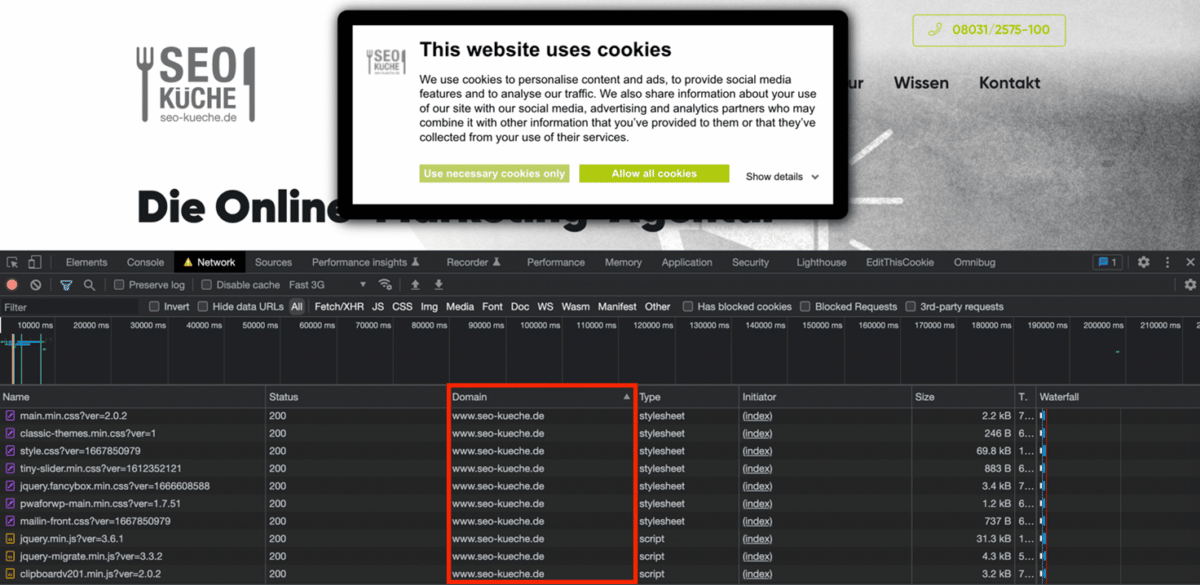
Beispiel für die Startseite von seo-kueche.de: Es werden nur unbedenkliche Ressourcen geladen.
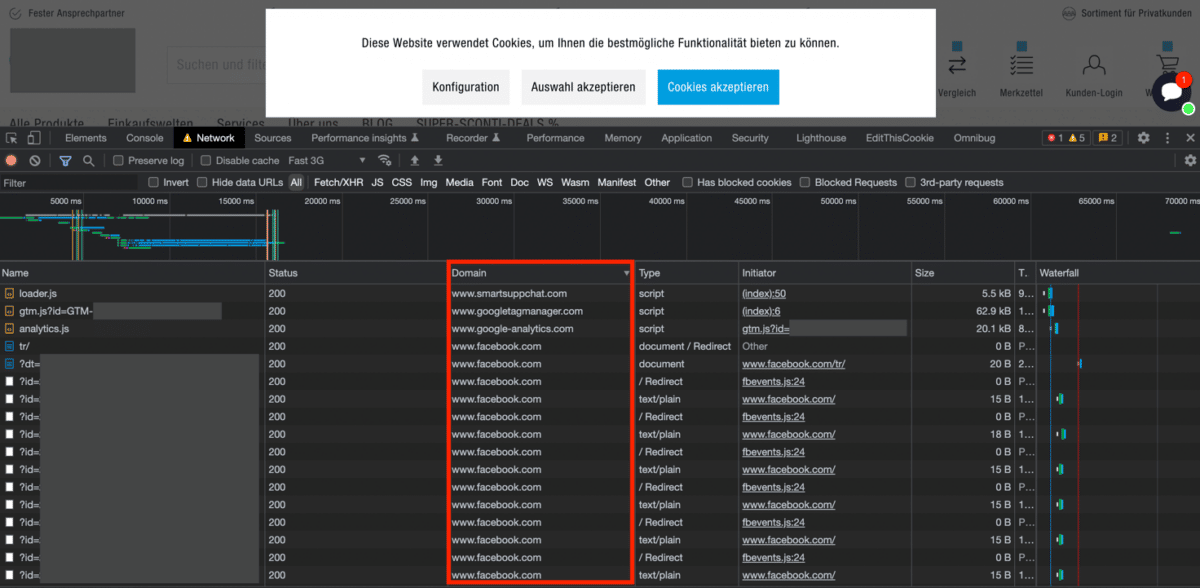
Für komplette Websites mit dem Screaming Frog SEO Spider
Mit der gezeigten Vorgehensweise über die Browser Entwickler-Tools kann das Laden von externen Ressourcen schnell für einzelne Unterseiten geprüft werden. Eine Überprüfung ganzer Websites ist damit aber nur schwer möglich, sobald diese eine gewisse Anzahl an Unterseiten überschreiten.
Für solche Fälle bietet sich die Nutzung des Tools Screaming Frog SEO Spider an. Der Screaming Frog SEO Spider ist ein in der Welt der Suchmaschinenoptimierung gern genutztes Tool, mit dem Struktur und Inhalt von Websites vollumfänglich erfasst („gecrawled“) werden können. Das gezeigte Vorgehen ist ausschließlich mit der kostenpflichtigen Version möglich.
Neben der Auswertung relevanter SEO-Informationen wie URL-Struktur, Seitentitel und -beschreibungen, Indexierungsanweisungen usw. lassen sich über spezielle Filter auch individuelle Informationen aus den HTML-Quelltexten der gecrawlten URLs extrahieren: https://www.screamingfrog.co.uk/web-scraping/
Um das Laden externer Ressourcen zu erfassen, wollen wir über Filteranweisungen die folgenden Informationen aus den HTML-Quelltexten auslesen:
- src-Attribute, die nicht zur untersuchten Website-Domain gehören (z. B. von <iframe>-Tags, <script>-Tags, direkt eingebundenen Elementen)
- href-Attribute von <link>-Tags, die nicht auf die untersuchte Website-Domain verweisen (z. B. CSS-Stylesheets, eingebundene Schriftarten)
- von <script>-Tags umschlossener (= direkt im HTML-Quellcode integrierter) JavaScript-Code, der einen Code-Bestandteil enthält, welcher auf eine Ressource verweist, die nicht zur untersuchten Website-Domain gehört (wie z. B. innerhalb eines Facebook Pixel Code Snippet – hier wird die Quelle für weiteren JavaScript-Code nicht über ein innerhalb des öffnenden <script>-Tags hinzugefügtes src-Attribut festgelegt, sondern innerhalb des zwischen den <script>-Tags eingefügten JavaScript-Codes generiert)
<script>
!function(f,b,e,v,n,t,s)
{if(f.fbq)return;n=f.fbq=function(){n.callMethod?
n.callMethod.apply(n,arguments):n.queue.push(arguments)};
if(!f._fbq)f._fbq=n;n.push=n;n.loaded=!0;n.version='2.0';
n.queue=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertBefore(t,s)}(window, document,'script',
'https://connect.facebook.net/en_US/fbevents.js');
fbq('init', '{your-pixel-id-goes-here}');
fbq('track', 'PageView');
</script>
Hinweis: Damit werden die gängigsten Einbindungsweisen für externe Ressourcen abgedeckt. Es kann jedoch nicht ausgeschlossen werden, dass einzelne Code-Versionen zur Einbindung von externen Ressourcen eine davon abweichende Struktur aufweisen und damit von den im Folgenden definierten Filter unerkannt bleiben.
Wir setzen die dargestellten Kriterien als XPath-Extraktionsfilter um. XPath ist eine Abfragesprache, mit der gezielt Teile von XML-Dokumenten angesprochen und ausgewertet werden können.
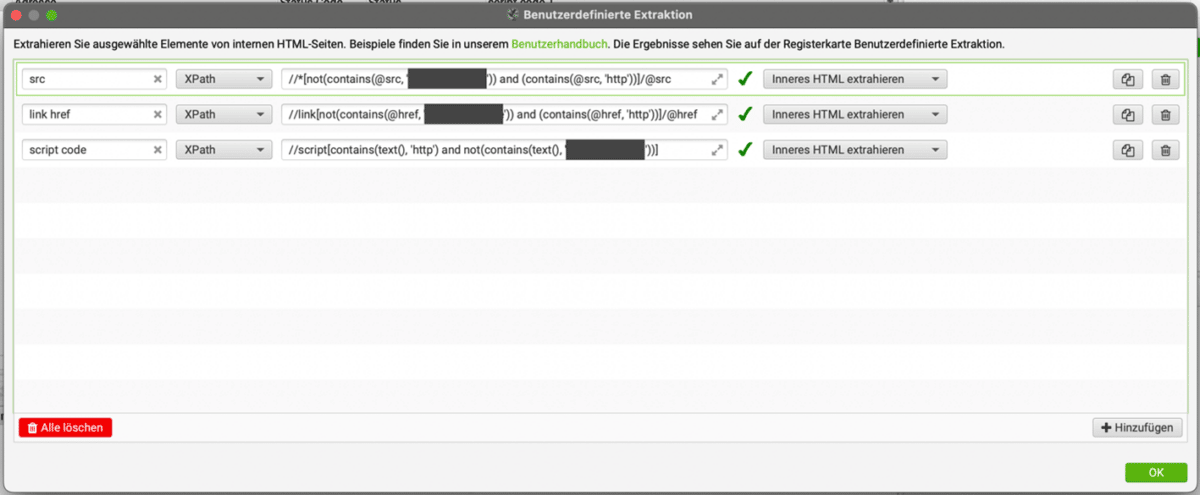
Für die drei oben genannten Kriterien lauten die XPath-Extraktionsfilter wie folgt:
//*[not(contains(@src, 'Domain der zu überprüfenden Website')) and (contains(@src, 'http'))]/@src//link[not(contains(@href, 'Domain der zu überprüfenden Website')) and (contains(@href, 'http'))]/@href//script[contains(text(), 'http') and not(contains(text(), 'Domain der zu überprüfenden Website'))]
Die ersten beiden Filter überprüfen die src-Attribute aller HTML-Elemente und die href-Attribute aller <link>-Tags, ob diese die Domain der zu überprüfenden Website enthalten (not(contains(@src, ‚Domain der zu überprüfenden Website‚)) bzw. not(contains(@href, ‚Domain der zu überprüfenden Website‚))) und ob diese als absolute Pfade angegeben sind (contains(@src, ‚http‘) bzw. contains(@href, ‚http‘)) – wenn sie als relative Pfade angegeben sind, dann liegen sie automatisch in derselben Domain wie die zu überprüfende Website). Verweisen die Attribute auf Ressourcen außerhalb der Domain der zu überprüfenden Website, dann wird das Attribut extrahiert (/@src bzw. /@href). Der dritte Filter überprüft zwischen <script>-Tags definierten JavaScript-Codes, ob diese eine URL mit absoluter Pfadangabe beinhalten (contains(text(), ‚http‘)). Wird darüber auf Ressourcen außerhalb der Domain der zu überprüfenden Website verwiesen, dann wird die Filterbedingung erfüllt (und der Inhalt zwischen den <script>-Tags über die untenstehende Filterkonfiguration im Screaming Frog SEO Spider extrahiert).
Im Screaming Frog SEO Spider hinterlegen wir die drei Filter unter Screaming Frog SEO Spider > Konfiguration > Benutzerdefiniert > Extraktion und aktivieren die Option „Inneres HTML extrahieren“.
Nun starten wir den Crawl der zu überprüfen Website. Nachdem der Crawl abgeschlossen ist, können die Ergebnisse der benutzerdefinierten Extraktionen im Tab „Benutzerdefinierte Extraktion“ des Hauptfensters eingesehen werden. Über das Dropdown-Auswahlfeld in der oberen linken Ecke können die Ergebnisse der beiden Extraktionsfilter durchgewechselt werden. Die gefunden externen Ressourcen finden sich in den weiteren Spalten der Ansicht.
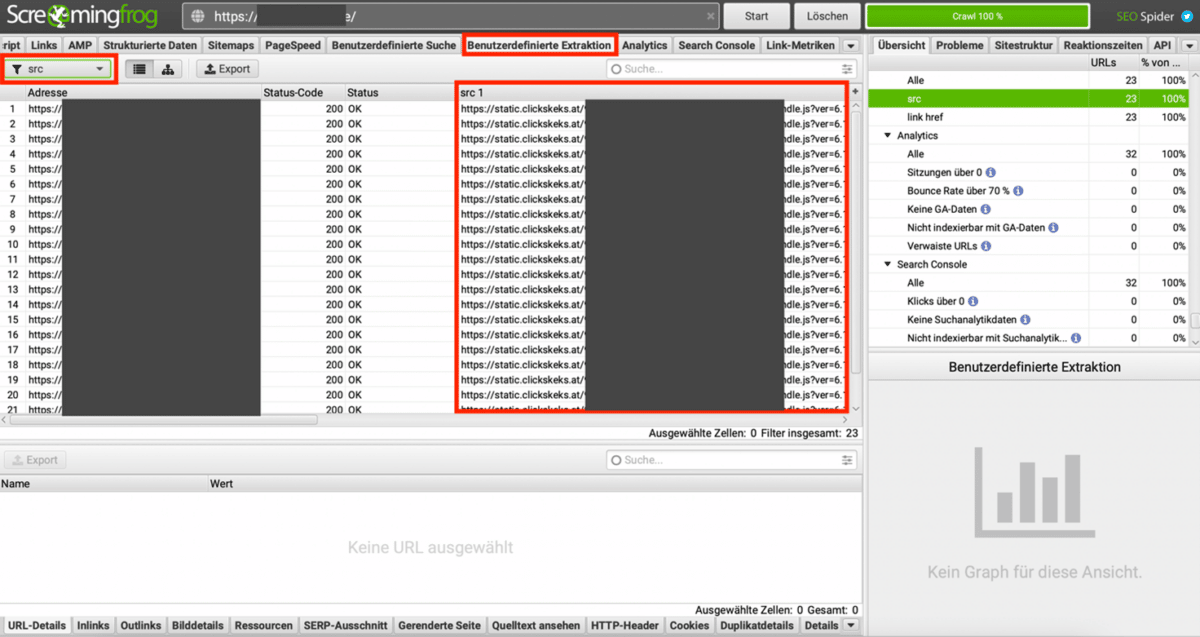
Im gezeigten Beispiel werden auf allen Seiten der Website bereits vor Nutzerzustimmung JavaScript-Ressourcen von der Domain static.clickskeks.at geladen (Spalte src 1).
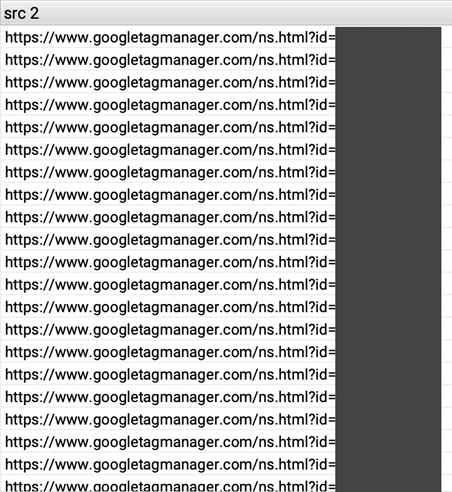
In der Spalte scr 2 findet sich auf allen gecrawlten URLs durchgehend Einträge mit der Quell-URL googletagmanager.com/ns.html. Das ist der <noscript>-Part des Google Tag Manager Code Snippets. Dieser wird für gewöhnlich als <iframe> im HTML-Quelltext eingefügt, um ein rudimentäres Tracking für Nutzer zu gewährleisten, die in ihrem Browser kein JavaScript aktiviert haben:
<noscript><iframe src="https://www.googletagmanager.com/ns.html?id=GTM-XXXXXXX" height="0" width="0" style="display:none;visibility:hidden"></iframe></noscript>
Das eigentliche JavaScript-Code-Snippet des Google Tag Managers wird von diesem XPath-Extraktionsfilter nicht abgedeckt. Dies wird sich im dritten Dropdown-Eintrag script code wiederfinden.
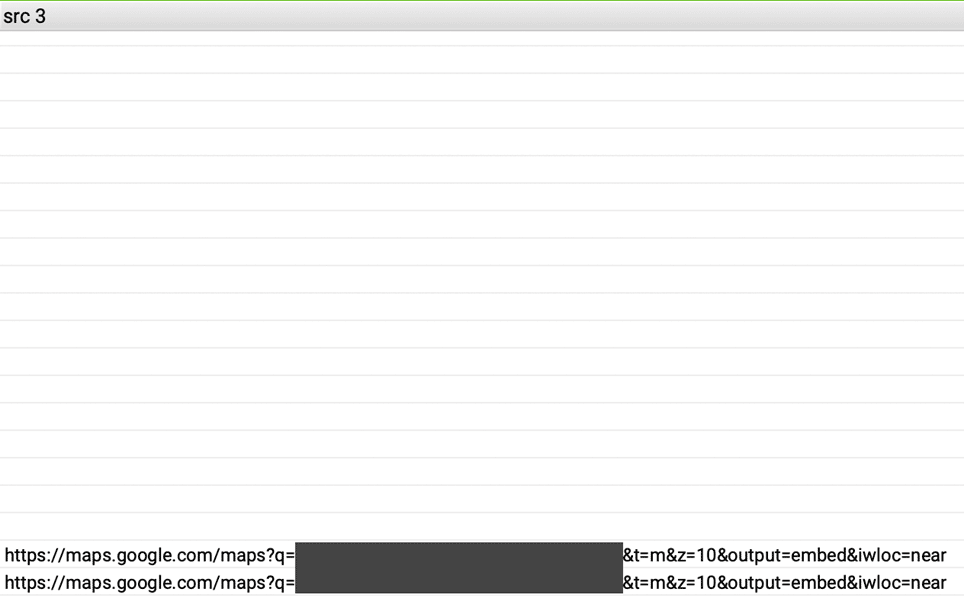
Für einige der gecrawlten URLs werden in der Spalte src 3 noch Einträge der Domain maps.google.com ausgegeben. Auf diesen Unterseiten ist anscheinend eine Karte von Google Maps eingebunden, die bereits vor Nutzerzustimmung geladen wird.
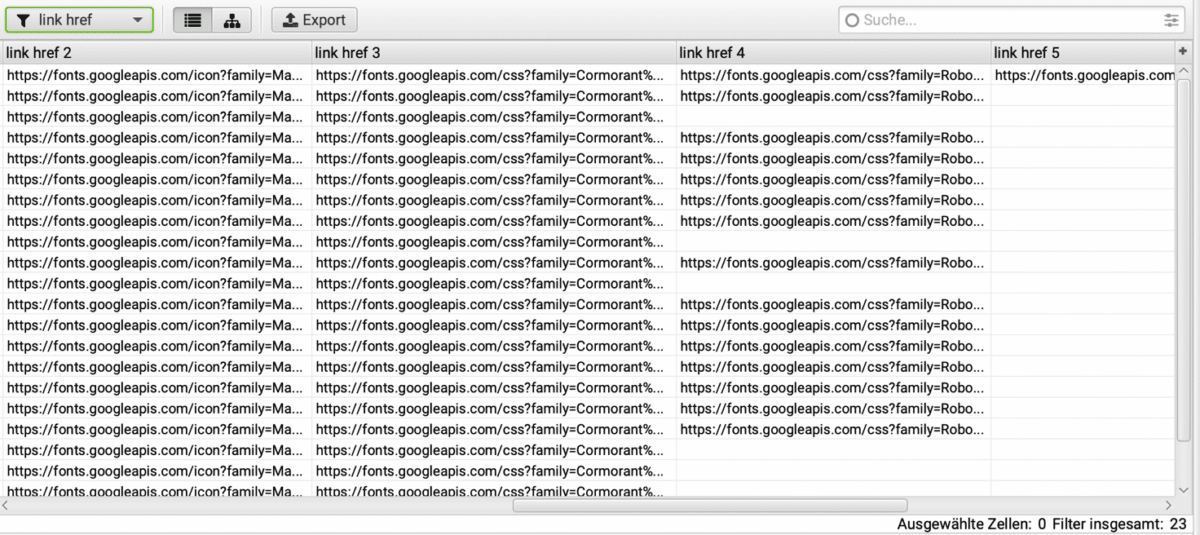
Für den Extraktionsfilter der href-Attribute aller <link>-Tags werden in mehreren Spalten Einträge der Domain fonts.googleapis.com ausgegeben. Das bedeutet, dass auf diesen gecrawlten URLs Schriftarten von Google Fonts direkt vom Google-Server geladen werden. Wären diese lokal in der Domain der untersuchten Website eingebunden, würden sie hier nicht auftauchen.
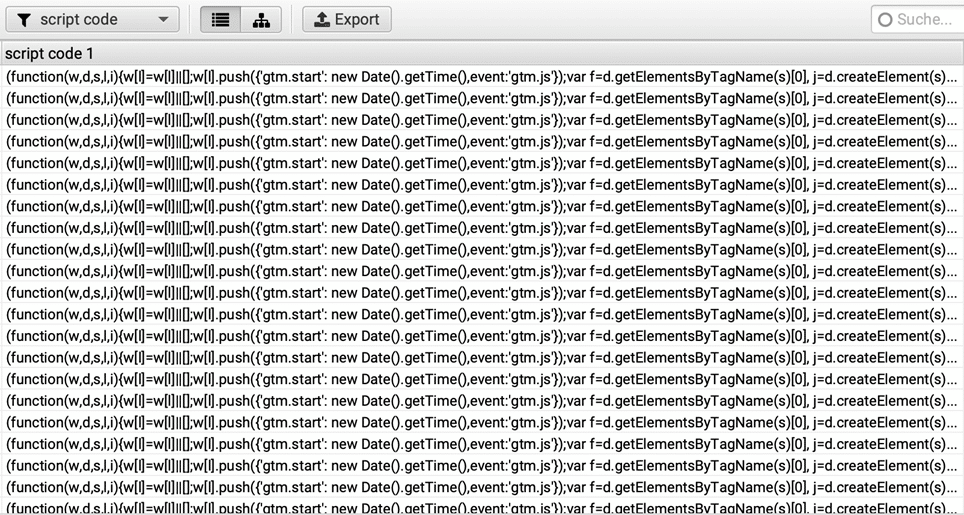
Die Ergebnisse des Extraktionsfilters für zwischen <script>-Tags eingefügte JavaScript-Code-Bestandteile lassen sich über den dritten Eintrag im Dropdown-Auswahlfeld oben links anzeigen. Hier findet sich für alle Seiten der überprüften Website der JavaScript-Code für die Einbindung des Google Tag Managers. Im Nachgang muss nun geprüft werden, ob dieser bereits vor Zustimmung durch die Website-Besucher*innen ausgelöst wird. Im konkreten Fall hatte sich bei Blick in den HTML-Quellcode herausgestellt, dass das öffnende <script>-Tag mit Anweisungen zum Zusammenspiel mit dem genutzten Cookie-Consent-Banner Cookiebot erweitert wurde:
<script type="text/plain" data-cookieconsent="statistics">(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({'gtm.start': new Date().getTime(),event:'gtm.js'});var f=d.getElementsByTagName(s)[0], j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';j.async=true;j.src='https://www.googletagmanager.com/gtm.js?id='+i+dl;f.parentNode.insertBefore(j,f);})(window,document,'script','dataLayer','GTM-XXXXXXX');</script>
Dementsprechend sind die gefundenen mit dem XPath-Extraktionsfilter gefundenen Einträge unproblematisch.
Fazit
Website-Betreiber*innen sind für alle Vorgänge, die auf ihrer Website passieren, verantwortlich. Dazu zählt auch sicherzustellen, dass externe Ressourcen nicht oder erst nach Zustimmung durch die Website-Besucher*innen geladen werden. Oftmals ist jedoch gar nicht ersichtlich, auf welchen Seiten der Website externe Ressourcen durch welche Dienste geladen werden. Mit den gezeigten Methoden ist es möglich, dies sowohl für einzelne Unterseiten als auch die komplette Website zu überprüfen.
Im weiteren Verlauf gilt es nun, das Laden der Website-Inhalte datenschutzkonform umzugestalten:
- Wenn möglich, sollten Ressourcen wie Schriftarten, Stylesheets, Bilder usw. immer lokal eingebunden werden.
- Codes für Tracking Tools, deren Server nicht innerhalb der eigenen Website-Domain laufen (z. B. Google Analytics, Google Tag Manager, Facebook Pixel), sollten im Zusammenspiel mit einem Cookie-Consent-Banner so ausgespielt werden, dass sie erst auslösen, nachdem Website-Besucher*innen ihre Zustimmung zur Nutzung des Dienstes gegeben haben. Die Umsetzung ist dabei immer vom konkreten Anbieter der zum Einsatz kommenden Cookie-Consent-Lösung abhängig. Oftmals muss dafür das vom Tracking-Tool-Anbieter zur Verfügung gestellte JavaScript-Code-Snippet angepasst werden. <noscript>-Parts sollten generell nicht mehr eingebunden werden.
- Per iframe eingebundene Inhalte wie YouTube-Videos, Twitter-Feeds o. ä. dürfen ebenfalls erst nach Zustimmung der Website-Besucher*innen geladen werden. Auch dies lässt sich im Zusammenspiel mit einer Cookie-Consent-Lösung umsetzen. Alternativ kann auf diese Inhalte auch klassisch verlinkt werden, so dass die Website-Besucher*innen nach Klick auf den Link direkt auf die Plattform gelangen und die Inhalte dort einsehen können.
Sie benötigen Unterstützung bei der datenschutzkonformen Implementierung von Tracking Tools oder der Einbindung von externen Inhalten wie Google Fonts, YouTube-Videos & Co.? Wir unterstützen Sie gern bei Ihren Vorhaben. Senden Sie uns gern eine unverbindliche Anfrage.
Titelbild © darkovujic / stock.adobe.com






Keine Kommentare vorhanden